
Écrire vos publis avec l’aide de ChatGPT ? Certains jetteront des regards outrés mais le fait est que la pratique se répand dans la littérature scientifique. Un an et demi après le lancement de l’intelligence artificielle (IA) générative par l’entreprise OpenAI, les études se multiplient sur les plateformes de preprint depuis un mois et montrent l’ampleur du phénomène. Les articles scientifiques présentant la marque d’une réécriture par un modèle de langage représentaient en 2023 entre 1 et 5% de la littérature scientifique. Deux études l’attestent : l’une déposée sur arXiv, l’autre sur bioRxiv. La seconde montre d’ailleurs une nette prépondérance du recours à l’IA dans le domaine de l’informatique (tiens, tiens) et dans les pays non anglophones, Italie et Chine en tête. Cet autre preprint montre la constante augmentation de l’utilisation des IA génératives dans les publis, s’élevant à 17% début 2024 en informatique, où 35% des abstracts auraient été reformulés par ChatGPT, estime cette plus récente analyse.
« ChatGPT peut facilement changer ce que vous vouliez dire »
Andrew Gray, University College London
Balzac ou Flaubert. Cette révolution s’accompagne d’un changement de style d’écriture : c’est d’ailleurs une façon d’estimer le poids de l’IA dans la littérature scientifique. Bibliothécaire à la University College London, Andrew Gray a repéré au moins 60 000 papiers avec la patte de l’IA parmi les 5 millions publiées en 2023 que recense la base Dimensions. S’inspirant de précédentes études sur la méthode, il a repéré l’usage de certains mots ou de certaines combinaisons : meticulous, intricate, commendable… Un vocabulaire « inhabituel et un peu trop soutenu » pour de la littérature scientifique, explique le bibliothécaire. La méthode statistique utilisée ne permet toutefois pas d’identifier individuellement et à coup sûr les articles retouchés.
De l’ivraie. Pourquoi l’utilisation de ChatGPT dans les publis soulève tant d’émoi ? On vous en parlait quelques mois après sa sortie : les modèles de langage ne distinguent pas le vrai du faux, d’où la présence de ce que beaucoup appellent aujourd’hui les “hallucinations” de ChatGPT – qui fait pourtant mieux que ses concurrents : Léonard de Vinci aurait peint Mona Lisa en 1815 et il n’y aurait eu qu’un seul survivant à la tragédie du Titanic, comme vous le savez tous. Les références scientifiques proposées par ChatGPT sont dans la majorité des cas fabriquées de toutes pièces, comme l’expliquait, horrifié, l’éditeur en chef de la revue Schizophrenia. L’IA semble donc parfaite pour écrire une fiction mais pas en recherche. La génération d’article scientifique par ChatGPT sans intervention humaine a d’ailleurs très vite été écartée par les éditeurs qui ont rapidement interdit de faire apparaître une IA parmi les auteurs.
« La frontière entre une bonne et une mauvaise utilisation est très fine »
Guillaume Cabanac, Université Paul Sabatier – Toulouse 3
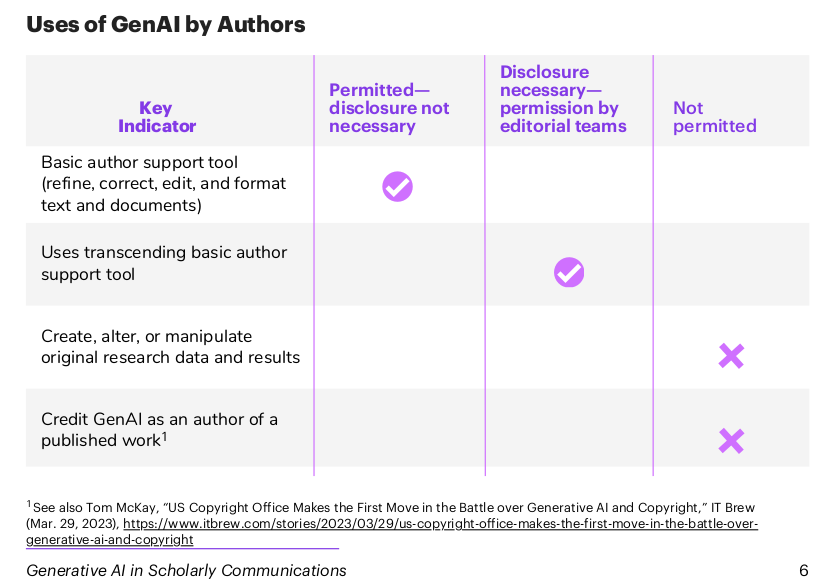
Do’s and don’t. En revanche, confier à une IA générative le contenu d’un manuscrit et la laisser reformuler, formater, corriger l’anglais… est de plus en plus courant et accepté. Sortis ces derniers mois, deux documents ont entériné le phénomène… et créé un remue-ménage dans l’édition scientifique. Le premier est le livre blanc de l’association d’éditeurs scientifiques STM, pesant pour deux tiers des publis mondiales. Dans un tableau à double entrée, elle catégorise de façon claire et nette les usages : pour ce qui est du “basic support tool” (raffiner son texte, le corriger, le formater…), les auteurs n’ont pas à le mentionner, tout ce qui « transcende cette utilisation de base » (faire un état de l’art, trouver la meilleure hypothèse ou méthode, analyser ses résultats…) doit être déclaré. Générer ses données ou images par l’IA (rappelez-vous celle du rongeur au sexe géant) et la faire apparaître au rang d’auteur du papier est fermement proscrit.
{kind=link}
LV1 / LV2. Nous l’avions prédit en janvier 2023 : ChatGPT est en train de devenir votre super correcteur d’orthographe. Mais quand elle reformule, l’IA générative ne peut apparemment pas s’empêcher d’ajouter de petites touches personnelles à tel point que « ChatGPT peut facilement changer ce que vous vouliez dire », prévient le bibliothécaire Andrew Gray. Un glissement d’autant plus pernicieux que les chercheurs ayant le plus besoin de ces fonctions sont les non anglophones : environ 8% des papiers de vos collègues italiens contiendraient des marques d’IA générative, contre pratiquement zéro chez les Britanniques, rapporte l’étude déposée sur bioRxiv et menée sur environ 45 000 preprints. Difficile de blâmer les chercheurs moins familiers avec la langue de Shakespeare, déjà victimes de profondes inégalités en termes de publication : « La frontière entre une bonne et une mauvaise utilisation est très fine », estime Guillaume Cabanac, enseignant-chercheur à l’Université Paul Sabatier – Toulouse 3 et spécialisé dans la chasse aux publications générées par IA.
« Nous devons faire confiance aux auteurs »
Marie Soulière, Frontiers
Avec précaution. La Commission européenne, qui publie ses nouvelles guidelines à destination des chercheurs et de leurs institutions (voir encadré pour ce second volet), apporte un début de réponse. L’institution rappelle que les auteurs seront toujours responsables de ce qu’ils publient, qu’ils aient recours non à une IA générative. En deux mots : prudence et transparence : le caractère aléatoire de l’IA peut donner des résultats différents avec pourtant les mêmes données en entrée. L’instance européenne met également les scientifiques en garde sur la confidentialité et la propriété intellectuelle, notamment quand il s’agit de résultats non publiés, sensibles ou des données personnelles. Car qui sait ce que deviennent les contenus que vous soumettez à ChatGPT, opérée par l’entreprise « but lucratif plafonné » OpenAI ? Ils pourraient très bien ressortir en réponse à la requête d’un autre chercheur, à l’autre bout du monde. Dans ce contexte, l’utilisation d’IA générative dans le travail de peer review ou de sélection d’appels à projet est fortement déconseillée. Pourtant, après analyse de quatre conférences récentes en informatique, les auteurs de ce preprint l’ont montré : jusqu’à 17% des rapports des reviewers avaient été retouchés par ChatGPT.
D’une seule voix. Sur le terrain, les maisons d’édition réagissent, pas toujours de manière synchrone. Si elles s’accordent sur l’interdiction stricte de l’autorat et de la génération de données ou d’illustration par les modèles de langage, les avis sont moins unanimes concernant ce qui doit être déclaré dans le manuscrit. Doit-on déclarer tous les usages, même basiques, ou bien uniquement les utilisations plus poussées des IA génératives ? Springer Nature propose par exemple, sans complexe, d’améliorer l’anglais de vos manuscrits avant soumission grâce à son nouvel outil Curie. En tant qu’auteur, il vous est donc conseillé de bien lire les politiques de chaque éditeur. Ceux-ci n’ont d’ailleurs qu’une marge de manœuvre limitée, en l’absence de moyen efficace pour détecter la patte de ChatGPT et consorts dans les manuscrits qui leur sont soumis – OpenAI a carrément abandonné en juillet dernier son propre détecteur, qui générait des faux positifs dans un cas sur 10 ! « Nous devons faire confiance aux auteurs », explique Marie Soulière, responsable qualité et éthique chez Frontiers et élue au sein du Committee on Publication Ethics (COPE). Ce dernier planche sur les dilemmes auxquels sont confrontés les éditeurs et publie régulièrement des fiches.
« Rétracter implique d’avoir la preuve que les conclusions ont été impactées [par l’utilisation d’IA »
Marie Soulière, Frontiers
Bond de géant. C’est donc avec intérêt que sont attendues – a priori pour cet été – les guidelines issues du projet CANGARU. Initié par l’urologue américain Giovanni Cacciamani et présenté dans ce preprint, il a pour but de trouver un consensus dans ce petit monde qu’est l’édition scientifique mais également de recenser les mauvais usages de l’IA générative. Un travail déjà bien entamé par le site Retraction Watch, qui liste l’ensemble des 92 papiers épinglés à l’heure actuelle par Guillaume Cabanac. Dans ces articles – pour lesquels l’usage d’une IA générative n’est pas déclaré –, la marque de ChatGPT est pourtant tellement évidente qu’elles sont de véritables « armes fumantes », ironise votre collègue toulousain qui donnait une conférence en mars à ce sujet. Les auteurs n’ont même pas pris la peine de retirer de leur manuscrit des commandes à l’intention de ChatGPT comme “Regenerate Response” ou des réponses typiques de l’IA telle que “Certainly! Here is…” et ce dès la première phrase de l’introduction. Et les papiers sont tranquillement passés à travers le peer review.
Mi-chemin. Guillaume Cabanac signale immédiatement toutes ces publications sur Pubpeer – on vous recommande vivement d’utiliser les extensions navigateur ou Zotero. Petite victoire pour l’intégrité : deux papiers comportant des “Regenerate Response” ont été rétractés, l’un par IOP Publishing, l’autre, comportant de surcroît rien moins que 18 références hallucinées, il y a quelques jours seulement par PLOS. Marie Soulière de chez Frontiers tempère : « Rétracter implique d’avoir la preuve que les conclusions ont été impactées. Autrement, on peut demander aux auteurs d’ajouter une phrase déclarant leur utilisation d’une IA générative ». La docteure en biochimie essaie d’imaginer un scénario enviable pour le futur : « ChatGPT pourrait permettre aux chercheurs de gagner du temps sur la rédaction à condition de relire attentivement, temps qu’ils pourraient consacrer à un peer review de qualité. » Quant à cet article, il a été généré à 100% par du jus de cerveau humain. On ne se refait pas…
Et vos employeurs dans tout ça ?
Les universités, organismes de recherche et agences de financement ont également leur rôle à jouer, comme le met en évidence la Commission européenne. Parmi ses recommandations : la formation des chercheurs, étudiants et autres personnels. Notre enquête sur l’utilisation de ChatGPT comme “secrétaire” pour les tâches administratives révélait en effet de fortes inégalités dans l’utilisation de ChatGPT et un coût d’entrée élevé pour une partie d’entre vous. La commission européenne recommande également aux établissements de surveiller les usages et d’héberger leur propre modèle de langage pour garder la main sur les données – tel Albert, la nouvelle IA de la fonction publique. L’aspect écologique et la gourmandise (en processeurs et en énergie) de telles IA déployées massivement n’est malheureusement que peu abordée.